文字化けについて|データ復旧
いまさら聞けないパソコン基礎知識
![]() データ復旧:トップ > いまさら聞けないパソコン基礎知識 > 文字化けについて
データ復旧:トップ > いまさら聞けないパソコン基礎知識 > 文字化けについて
文字化けについて

ホームページやメール、ファイルを開くと意味不明な文字の羅列が表示されることがあります。いわゆる「文字化け」と呼ばれる現象です。
どういった理由で文字が化けるのか、その仕組みと対応について解説します。
文字コードと文字集合
コンピュータは全てのデータを数値として扱っています。文字については、あらかじめ使用する文字1つ1つに番号が割り振られていて、文字と番号の組み合わせのことを「文字コード」といいます。
また、アルファベットの「A」から「Z」、ひらがなの「あ」から「ん」などのひとかたまりの文字を「文字集合」と呼びます。数字、かな、漢字を含めた日本語で使われる文字全体を指す大きなまとまりの「文字集合」もあります。日本語の文字集合の規格は日本工業規格(JIS)で定められています。
文字化けの歴史
数値と文字をマッチングさせるだけの単純な仕組みなのに、なぜ文字化けが発生するのかというと、日本語の文字集合一つに対して、複数の文字コードが存在するためです。UNIXでは"EUC-JP"、一般のパソコンでは"Shift-JIS"、電子メールでは"ISO-2022-JP"が主に使われていました。さらに記号などの特殊な文字をメーカー独自に追加していることもあります。これは一般に「機種依存文字」と呼ばれます。
仕組みの違うコンピュータ同士でデータのやり取りが無かった時代はそれでも問題はでなかったのですが、パソコン通信の時代から環境が異なる同士でのデータのやり取りが始まると、異文字コード同士を翻訳する仕組みが必要になり、その際の翻訳ミスがいわゆる「文字化け」の原因となります。
文字化けの例として単純なものでは、"Shift-JIS"と思って翻訳したら実は"EUC-JP"だった場合などになります。
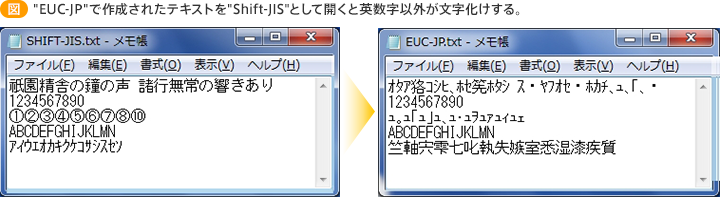
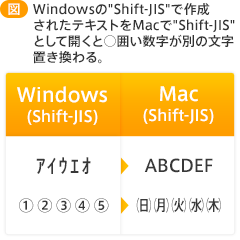
また、前述の機種依存文字も文字化けの大きな要因となっていました。具体的には半角カタカナや○囲い数字などが、特定の文字コードには存在しなかったり、別の文字と番号が被っていたりしたため、文字化けが発生する原因になっていました。
こういったトラブルは、使われている文字コードを自動判別する機能の向上や文字コードの使用ルールの徹底などで徐々に減りました。
例えば"ISO-2022-JP"では半角カタカナに対応していないので、メールソフトによっては文章内に半角カタカナが含まれると"UTF-8"などの対応した文字コードに自動で置き換える機能が備わっています。
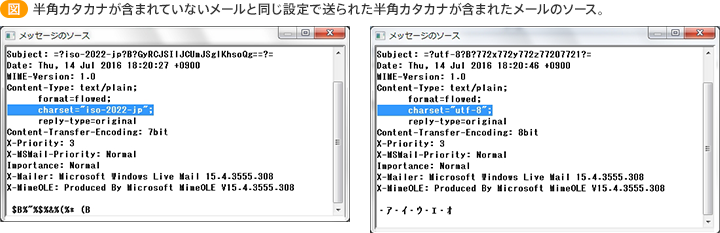
ただし、対応にも限界がある上に、携帯電話などの新しいプラットホームが出てくると、そこで使われていた独自の絵文字がまた機種依存文字になるなど、文字化けは減っても無くなることはありませんでした。
そこで、抜本的な解決策として提案されたのが、世界中のすべての文字を一つの「文字集合」にまとめようとしたUnicode(ユニコード)です。ユニコードを表現するための文字コードも複数ありますが、代表的なものがUTF-8です。
ユニコードの登場
ユニコードは「世界中の文字を一貫した方法で表現する」というのがそもそもの目的です。
これにより、手間をかけなくても同じ画面上で異なる文字を同時に表示させることが可能になりました。
文字化けに対しては、まずユニコードは機種依存文字も含めた世界中ですでに出回っているほぼ全ての文字を取り揃えているため、機種依存文字が原因となる文字化けもほぼ回避されるようになりました。さらにユニコードが採用されているシステムでは、異文字コード同士での翻訳の際でも一旦ユニコードを介する手順を踏むことになったので、異なる文字コード間の無数の組み合わせを考慮する必要がなくなり、各文字コードはユニコードとの対応だけ行えばよくなりました。
ユニコードが登場してしばらくは多少の混乱もありましたが、WindowsやMacなどの主要OSに取り入れられ、各種のアプリケーションやフォントも対応が始まり、現在においてはユニコードへの対応というのは当たり前のものになってきています。
ユニコードでも文字化け
しかし、ユニコードの導入で全てが解決したというわけではなく、また別の原因による文字化けが発生しています。

例えば波ダッシュ(波線)問題があります。「〜」の文字は、"上がって下がる"字形ですが、さらにほぼ同じ形の文字が「全角チルダ」という名称でも登録されています。Unicode7.0の時代に波ダッシュが上下反転した"下がって上がる"形の文字が波ダッシュとして登録されていたため、別の文字コードから変換する際に反転した文字が表示される、波ダッシュではなく全角チルダに変換される、文字化けして?マークになるなどの問題が発生していました。この問題はUnicode8.0においては修正されています。
また、ユニコードは2016年6月21日の段階でバージョン9まで更新されており、128,172文字が収録されています。約111万文字分の領域は確保されているため、年々様々な文字が追加されており、現在のバージョンには、携帯の絵文字や麻雀牌、各種のシンボルマークなども含まれています。このバージョンの違いで、作成者側が期待している通りの文字が全ての環境で表示されるとは限らないというケースもあります。
しかし、ユニコード以前の混乱と混迷の時代に比べると、その展望は明るいでしょう。近い将来に「文字化け」は過去の思い出話の中にしか存在しなくなるかもしれません。
文字化けした場合の対応
最新の文化とも言えるスマートフォンですが、文字化けについて言うと、古い時代の文字化けがまだ頻発しているようです。
Android搭載のスマートフォンではユニコードが搭載されており、ベースの文字コードもユニコードの"UTF-8"となっています。一方、日本語環境のWindowsパソコンで、テキストファイルを作成すると通常は従来の"Shift-JIS"が使われます。
このAndroid搭載スマートフォンにてパソコンなどで作成されたテキストファイルを開くと翻訳ミスによる文字化けをすることがよくあります。テキストファイルを開くアプリケーション(エディター)側の設定の問題や、そもそも異文字コードに対応していないシンプルなエディターが標準的に使われることが多いというのが原因のようです。またWindowsやMacで標準設定されている"メモ帳"や"テキストエディタ"でも、最低限の文字コード判別機能しかついていないため、条件によっては文字化けすることがあります。
こういった文字化けを避ける最も簡単な解決方法は、文字コードを自動で判別するアプリでテキストファイルを開くことです。
WindowsやMacでしたら、高機能なエディタソフトやWordなどの文書作成ソフト、InternetExplolerやSafariなどのブラウザもお勧めです。
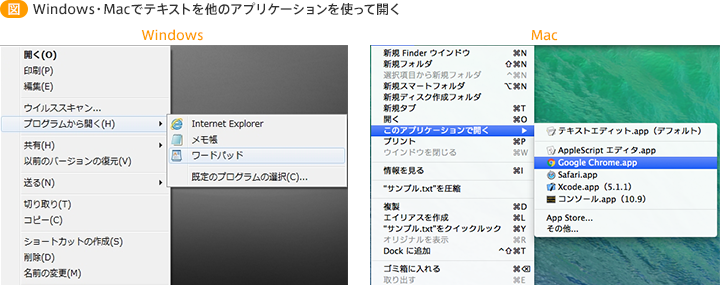
スマートフォンの場合は各ストアで対応している文字コードの自動変換に対応しているエディターを確認しましょう。
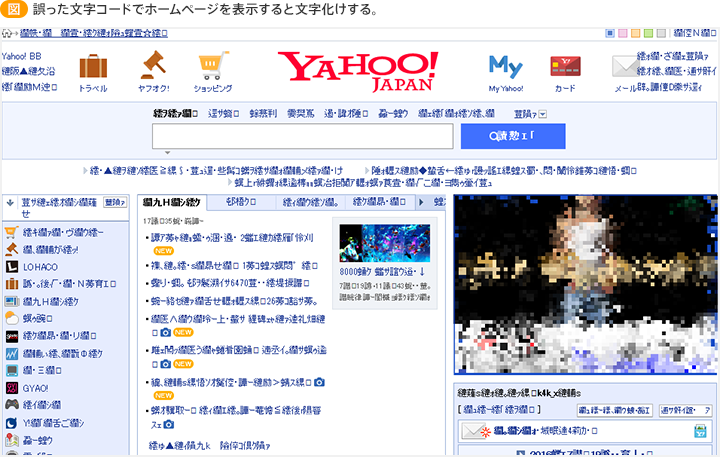
ホームページの閲覧時や受信したメールが文字化けする事例は、ユニコード登場以前に比べるとはるかに頻度が減りましたが、古い時代に作成されたまま手入れがされていないホームページや、ガラケー時代の設定が残っている一部のメールサーバーではまだ文字化けが発生することがあります。
WindowsやMacでは閲覧に使っているソフトウェア上で文字コード(エンコード)の設定を変更することで別の文字コードをその場で試すことが可能です。
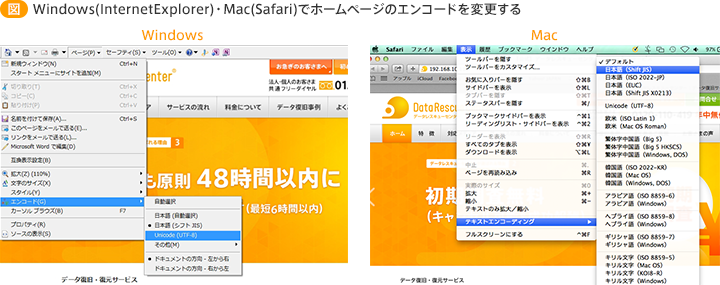
スマートフォンでは、一部のソフトウェアではそういった機能が備わっていないものがあります。別のブラウザやメールソフトを試してみましょう。
障害による文字化け
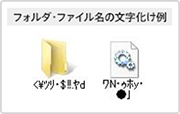
文字コードの違い以外の原因でも文字化けが発生することがあります。記録媒体になんらかの障害が発生して、ファイル名やフォルダ名が文字化けすることがあります。この文字化けは障害の影響でマスターファイルテーブルにあるファイル名の情報そのものが書き換わることが原因となるため、解消することは出来ません。また、ファイルの中身まで書き換わることもあり、ファイルが開かなくなる場合がありますが、こういった場合でもデータ復旧に対応しておりますので、ファイル名が文字化けした場合は一度ご相談ください。
マスターファイルテーブル(Master File Table・MFT)とは
















![]()



